bufio
22 分钟阅读
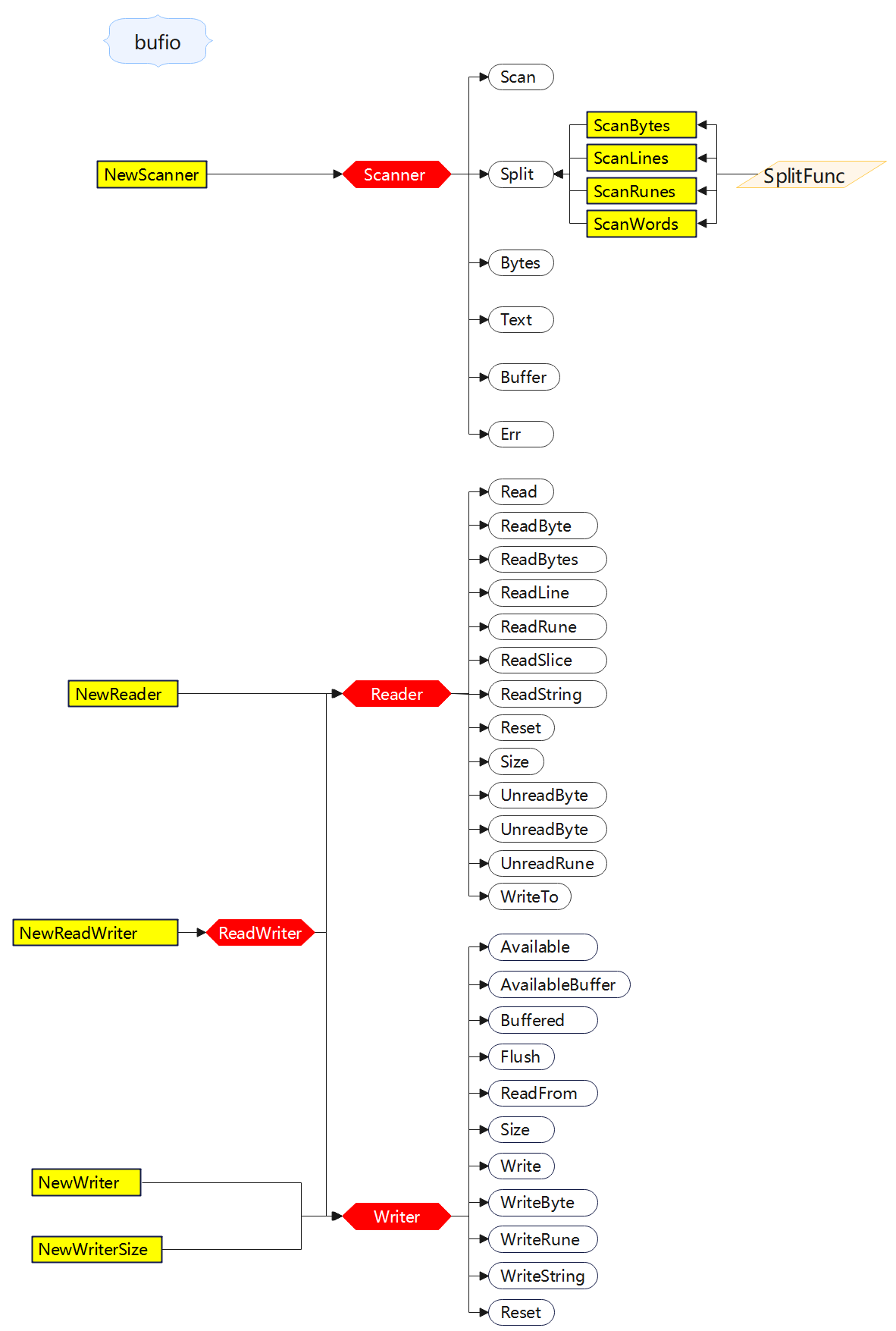
Package bufio implements buffered I/O. It wraps an io.Reader or io.Writer object, creating another object (Reader or Writer) that also implements the interface but provides buffering and some help for textual I/O.
bufio包实现了带缓冲的 I/O 操作。它包装了一个 io.Reader 或 io.Writer 对象,创建另一个实现相同接口的对象(Reader 或 Writer),但提供了缓冲和一些文本 I/O 的辅助。
常量
| |
变量
| |
| |
Errors returned by Scanner.
由Scanner返回的错误。
| |
ErrFinalToken is a special sentinel error value. It is intended to be returned by a Split function to indicate that the token being delivered with the error is the last token and scanning should stop after this one. After ErrFinalToken is received by Scan, scanning stops with no error. The value is useful to stop processing early or when it is necessary to deliver a final empty token. One could achieve the same behavior with a custom error value but providing one here is tidier. See the emptyFinalToken example for a use of this value.
ErrFinalToken 是一个特殊的错误值,用作分割函数的返回值。它的作用是告诉 Scan 函数返回的标记是最后一个标记,扫描应该在此标记后停止。在 Scan函数收到 ErrFinalToken 后,扫描将无错误地停止。这个值在需要提前停止处理或需要传递一个最终的空标记时很有用。虽然可以使用自定义错误值实现相同的行为,但在这里提供一个固定的值更加方便。可以查看 emptyFinalToken 示例 )以了解此值的使用方法。
函数
func ScanBytes <- go1.1
| |
ScanBytes is a split function for a Scanner that returns each byte as a token.
ScanBytes函数是一个用于 Scanner 的分割函数,将每个字节作为一个标记返回。
| |
func ScanLines <- go1.1
| |
ScanLines is a split function for a Scanner that returns each line of text, stripped of any trailing end-of-line marker. The returned line may be empty. The end-of-line marker is one optional carriage return followed by one mandatory newline. In regular expression notation, it is \r?\n. The last non-empty line of input will be returned even if it has no newline.
ScanLines函数是一个用于 Scanner 的分割函数,返回每行文本,删除任何尾随的行尾标记。返回的行可能为空。行尾标记是一个可选的回车符后跟一个必需的换行符。在正则表达式符号中,它是 \r?\n。即使最后一个非空行没有换行符,它也会被返回。
func ScanRunes <- go1.1
| |
ScanRunes is a split function for a Scanner that returns each UTF-8-encoded rune as a token. The sequence of runes returned is equivalent to that from a range loop over the input as a string, which means that erroneous UTF-8 encodings translate to U+FFFD = “\xef\xbf\xbd”. Because of the Scan interface, this makes it impossible for the client to distinguish correctly encoded replacement runes from encoding errors.
ScanRunes函数是一个用于 Scanner 的分割函数,返回每个 UTF-8 编码的符文作为一个标记。返回的符文序列等同于作为字符串遍历输入的范围循环的符文序列,这意味着错误的 UTF-8 编码将被翻译为 U+FFFD = “\xef\xbf\xbd"。由于 Scan 接口的限制,这使得客户端无法区分正确编码的替换符与编码错误。
func ScanWords <- go1.1
| |
ScanWords is a split function for a Scanner that returns each space-separated word of text, with surrounding spaces deleted. It will never return an empty string. The definition of space is set by unicode.IsSpace.
ScanWords函数是一个用于 Scanner 的分割函数,返回每个以空格分隔的文本单词,删除周围的空格。它永远不会返回空字符串。空格的定义由 unicode.IsSpace 设置。
类型
type ReadWriter
| |
ReadWriter stores pointers to a Reader and a Writer. It implements io.ReadWriter.
ReadWriter结构体存储指向 Reader 和 Writer 的指针。它实现了 io.ReadWriter。
func NewReadWriter
| |
NewReadWriter allocates a new ReadWriter that dispatches to r and w.
NewReadWriter函数分配一个新的 ReadWriter,将其分派给 r 和 w。
| |
type Reader
| |
Reader implements buffering for an io.Reader object.
Reader结构体为 io.Reader 对象实现缓冲。
func NewReader
| |
NewReader returns a new Reader whose buffer has the default size.
NewReader函数返回一个具有默认大小的新 Reader。
func NewReaderSize
| |
NewReaderSize returns a new Reader whose buffer has at least the specified size. If the argument io.Reader is already a Reader with large enough size, it returns the underlying Reader.
NewReaderSize函数返回一个具有至少指定大小的新 Reader。如果参数 io.Reader 已经是一个具有足够大的大小的 Reader,则返回底层 Reader。
(*Reader) Buffered
| |
Buffered returns the number of bytes that can be read from the current buffer.
Buffered方法返回当前缓冲区中可以读取的字节数。
(*Reader) Discard <- go1.5
| |
Discard skips the next n bytes, returning the number of bytes discarded.
Discard方法跳过接下来的 n 个字节,返回已丢弃的字节数。
If Discard skips fewer than n bytes, it also returns an error. If 0 <= n <= b.Buffered(), Discard is guaranteed to succeed without reading from the underlying io.Reader.
如果 Discard 跳过的字节数少于 n,则还会返回一个错误。如果 0 <= n <= b.Buffered(),则保证 Discard 在不从底层 io.Reader 读取的情况下成功执行。
(*Reader) Peek
| |
Peek returns the next n bytes without advancing the reader. The bytes stop being valid at the next read call. If Peek returns fewer than n bytes, it also returns an error explaining why the read is short. The error is ErrBufferFull if n is larger than b’s buffer size.
Peek方法返回下一个 n 个字节,但不推进读取器。在下一次读取调用时,这些字节将不再有效。如果 Peek 返回少于 n 个字节,则还会返回一个说明读取不足的错误。如果 n 大于 b 的缓冲区大小,则该错误为 ErrBufferFull。
Calling Peek prevents a UnreadByte or UnreadRune call from succeeding until the next read operation.
调用 Peek 会阻止 UnreadByte 或 UnreadRune 调用成功,直到下一次读取操作。
(*Reader) Read
| |
Read reads data into p. It returns the number of bytes read into p. The bytes are taken from at most one Read on the underlying Reader, hence n may be less than len(p). To read exactly len(p) bytes, use io.ReadFull(b, p). If the underlying Reader can return a non-zero count with io.EOF, then this Read method can do so as well; see the io.Reader docs.
Read方法读取数据到 p 中,并返回读取到 p 中的字节数。这些字节最多从底层 Reader 的一个 Read 中取出,因此 n 可能小于 len(p)。要读取确切的 len(p) 个字节,请使用 io.ReadFull(b, p)。如果底层 Reader 在 io.EOF 时返回非零计数,则此 Read 方法也可以这样做;请参见 io.Reader文档。
(*Reader) ReadByte
| |
ReadByte reads and returns a single byte. If no byte is available, returns an error.
ReadByte方法读取并返回一个字节。如果没有可用字节,则返回一个错误。
(*Reader) ReadBytes
| |
ReadBytes reads until the first occurrence of delim in the input, returning a slice containing the data up to and including the delimiter. If ReadBytes encounters an error before finding a delimiter, it returns the data read before the error and the error itself (often io.EOF). ReadBytes returns err != nil if and only if the returned data does not end in delim. For simple uses, a Scanner may be more convenient.
ReadBytes方法读取直到输入中第一次出现分隔符 delim,返回包含数据和分隔符的切片。如果 ReadBytes 在找到分隔符之前遇到错误,它将返回读取的数据和错误本身(通常是 io.EOF)。如果返回的数据不以 delim 结尾,则 ReadBytes 返回 err != nil。对于简单的用途,使用Scanner结构体的方法可能更方便。
(*Reader) ReadLine
| |
ReadLine is a low-level line-reading primitive. Most callers should use ReadBytes(’\n’) or ReadString(’\n’) instead or use a Scanner.
ReadLine方法是一个低级别的读取行操作。大多数调用者应该使用 ReadBytes('\n') 或 ReadString('\n'),或使用 Scanner结构体的方法。
ReadLine tries to return a single line, not including the end-of-line bytes. If the line was too long for the buffer then isPrefix is set and the beginning of the line is returned. The rest of the line will be returned from future calls. isPrefix will be false when returning the last fragment of the line. The returned buffer is only valid until the next call to ReadLine. ReadLine either returns a non-nil line or it returns an error, never both.
ReadLine方法尝试返回一行,不包括行尾的字节。如果行太长以至于超过了缓冲区,则 isPrefix 被设置并返回该行的开头。该行的其余部分将从未来的调用中返回。在返回行的最后一个片段时,isPrefix 将为 false。返回的缓冲区仅在下一次调用 ReadLine 之前有效。ReadLine 要么返回非 nil 行,要么返回错误,但不会同时返回。
The text returned from ReadLine does not include the line end ("\r\n” or “\n”). No indication or error is given if the input ends without a final line end. Calling UnreadByte after ReadLine will always unread the last byte read (possibly a character belonging to the line end) even if that byte is not part of the line returned by ReadLine.
从 ReadLine方法返回的文本不包括行尾符("\r\n" 或 "\n")。如果输入结束时没有最终的行尾符,则不提供指示或错误。调用 ReadLine 后调用 UnreadByte 将始终撤消最后一个读取的字节(可能是属于行尾符的字符),即使该字节不是 ReadLine方法返回的行的一部分。
(*Reader) ReadRune
| |
ReadRune reads a single UTF-8 encoded Unicode character and returns the rune and its size in bytes. If the encoded rune is invalid, it consumes one byte and returns unicode.ReplacementChar (U+FFFD) with a size of 1.
ReadRune方法读取一个 UTF-8 编码的 Unicode 字符,并返回该字符及其字节数。如果编码的字符无效,则它将消耗一个字节,并返回 unicode.ReplacementChar(U+FFFD),大小为 1。
ReadRune Example
| |
(*Reader) ReadSlice
| |
ReadSlice reads until the first occurrence of delim in the input, returning a slice pointing at the bytes in the buffer. The bytes stop being valid at the next read. If ReadSlice encounters an error before finding a delimiter, it returns all the data in the buffer and the error itself (often io.EOF). ReadSlice fails with error ErrBufferFull if the buffer fills without a delim. Because the data returned from ReadSlice will be overwritten by the next I/O operation, most clients should use ReadBytes or ReadString instead. ReadSlice returns err != nil if and only if line does not end in delim.
ReadSlice方法读取直到输入中第一次出现分隔符 delim,返回指向缓冲区中字节的切片。这些字节在下一次读取时将不再有效。如果 ReadSlice 在找到分隔符之前遇到错误,则返回缓冲区中的所有数据以及错误本身(通常是 io.EOF)。如果缓冲区填满但没有出现分隔符,则 ReadSlice 失败并返回错误 ErrBufferFull。因为 ReadSlice 返回的数据将被下一个 I/O 操作覆盖,所以大多数客户端应该使用 ReadBytes 或 ReadString。如果 line 不以 delim 结尾,则 ReadSlice 返回 err != nil。
ReadSlice Example
| |
(*Reader) ReadString
| |
ReadString reads until the first occurrence of delim in the input, returning a string containing the data up to and including the delimiter. If ReadString encounters an error before finding a delimiter, it returns the data read before the error and the error itself (often io.EOF). ReadString returns err != nil if and only if the returned data does not end in delim. For simple uses, a Scanner may be more convenient.
ReadString方法读取直到在输入中第一次出现分隔符 delim,返回一个包含直到分隔符(包含分隔符)的数据的字符串。如果在找到分隔符之前遇到错误,它将返回错误之前读取的数据和错误本身(通常是 io.EOF)。如果返回的数据不以分隔符结束,则 ReadString 将返回 err != nil。对于简单的用法,可以使用 Scanner 更方便。
(*Reader) Reset <- go1.2
| |
Reset discards any buffered data, resets all state, and switches the buffered reader to read from r. Calling Reset on the zero value of Reader initializes the internal buffer to the default size.
Reset方法丢弃任何缓冲数据,重置所有状态,并将缓冲读取器切换到从 r 读取。在 Reader 的零值上调用 Reset 将初始化内部缓冲区为默认大小。
(*Reader) Size <- go1.10
| |
Size returns the size of the underlying buffer in bytes.
Size方法返回底层缓冲区的大小(以字节为单位)。
(*Reader) UnreadByte
| |
UnreadByte unreads the last byte. Only the most recently read byte can be unread.
UnreadByte方法取消读取最后一个字节。只能取消读取最近读取的字节。
UnreadByte returns an error if the most recent method called on the Reader was not a read operation. Notably, Peek, Discard, and WriteTo are not considered read operations.
如果最近在 Reader 上调用的方法不是读取操作,则 UnreadByte 返回错误。请注意,Peek、Discard 和 WriteTo 不被视为读取操作。
UnreadByte Example
| |
(*Reader) UnreadRune
| |
UnreadRune unreads the last rune. If the most recent method called on the Reader was not a ReadRune, UnreadRune returns an error. (In this regard it is stricter than UnreadByte, which will unread the last byte from any read operation.)
UnreadRune方法取消读取最后一个符文。如果在 Reader 上最近调用的方法不是 ReadRune,则 UnreadRune 返回错误。(在这方面,它比 UnreadByte 更严格,后者可以取消读取任何读取操作中的最后一个字节。)
(*Reader) WriteTo <- go1.1
| |
WriteTo implements io.WriterTo. This may make multiple calls to the Read method of the underlying Reader. If the underlying reader supports the WriteTo method, this calls the underlying WriteTo without buffering.
WriteTo方法实现了 io.WriterTo。这可能会多次调用底层 Reader 的 Read 方法。如果底层 Reader 支持 WriteTo 方法,则不使用缓冲区调用底层的 WriteTo方法。
type Scanner <- go1.1
| |
Scanner provides a convenient interface for reading data such as a file of newline-delimited lines of text. Successive calls to the Scan method will step through the ’tokens’ of a file, skipping the bytes between the tokens. The specification of a token is defined by a split function of type SplitFunc; the default split function breaks the input into lines with line termination stripped. Split functions are defined in this package for scanning a file into lines, bytes, UTF-8-encoded runes, and space-delimited words. The client may instead provide a custom split function.
Scanner结构体为读取数据(如文本行的以换行符分隔的文件)提供了一种便利的接口。连续调用 Scan 方法将通过文件的"tokens"步进,跳过标记之间的字节。标记的规范由类型为 SplitFunc 的分割函数定义;默认的分割函数将输入分解为带有行终止符的行。在本包中定义了用于将文件扫描为行、字节、UTF-8 编码符文和以空格分隔的单词的分割函数。客户端可以提供自定义分割函数。
Scanning stops unrecoverably at EOF, the first I/O error, or a token too large to fit in the buffer. When a scan stops, the reader may have advanced arbitrarily far past the last token. Programs that need more control over error handling or large tokens, or must run sequential scans on a reader, should use bufio.Reader instead.
扫描器在遇到EOF、第一个I/O错误或者无法容纳在缓冲区中的超大token时会停止不可恢复地扫描。当扫描器(Scanner)停止扫描时,读取器(Reader)可能会在最后一个标记(token)之后任意移动多个字节的位置。需要更多控制错误处理或大型token,或必须对读取器运行顺序扫描的程序,应改用bufio.Reader。
“When a scan stops, the reader may have advanced arbitrarily far past the last token. "
这句话的意思是,当扫描器(Scanner)停止扫描时,读取器(Reader)可能会在最后一个标记(token)之后任意移动多个字节的位置。也就是说,即使扫描器停止扫描了,读取器仍然可以继续读取数据,而这些数据可能并不是标记的一部分。这个特性可能会对一些应用程序造成困扰,需要注意处理。
Example(Custom)
Use a Scanner with a custom split function (built by wrapping ScanWords) to validate 32-bit decimal input.
使用自定义的分割函数(通过封装ScanWords)和Scanner一起验证32位十进制输入。
| |
Example(EmptyFinalToken)
Use a Scanner with a custom split function to parse a comma-separated list with an empty final value.
使用自定义的分割函数和Scanner解析逗号分隔的列表,其中包含一个空的最后一个值。
| |
Example(Lines)
The simplest use of a Scanner, to read standard input as a set of lines.
最简单的Scanner用法,将标准输入读取为一组行。
| |
Example(Words)
Use a Scanner to implement a simple word-count utility by scanning the input as a sequence of space-delimited tokens.
使用Scanner来实现一个简单的字数统计工具,将输入作为一个以空格分隔的符号序列来扫描。
使用Scanner实现一个简单的单词计数实用程序,通过将输入作为一系列以空格分隔的标记进行扫描。
| |
func NewScanner <- go1.1
| |
NewScanner returns a new Scanner to read from r. The split function defaults to ScanLines.
NewScanner函数返回一个从r中读取数据的新Scanner。默认情况下,分割函数为ScanLines。
(*Scanner) Buffer <- go1.6
| |
Buffer sets the initial buffer to use when scanning and the maximum size of buffer that may be allocated during scanning. The maximum token size is the larger of max and cap(buf). If max <= cap(buf), Scan will use this buffer only and do no allocation.
Buffer方法设置在扫描期间使用的初始缓冲区以及可能分配的最大缓冲区大小。最大标记大小是max和cap(buf)中的较大者。如果max <= cap(buf),则Scan方法将仅使用此缓冲区并且不进行分配。
By default, Scan uses an internal buffer and sets the maximum token size to MaxScanTokenSize.
默认情况下,Scan方法使用内部缓冲区并将最大标记大小设置为MaxScanTokenSize。
Buffer panics if it is called after scanning has started.
如果在扫描开始后调用Buffer方法,则会引发panic。
(*Scanner) Bytes <- go1.1
| |
Bytes returns the most recent token generated by a call to Scan. The underlying array may point to data that will be overwritten by a subsequent call to Scan. It does no allocation.
Bytes方法返回最近一次由Scan方法生成的标记。底层数组可能指向将被后续调用Scan覆盖的数据。它不会进行分配。
Bytes Example
Return the most recent call to Scan as a []byte.
| |
(*Scanner) Err <- go1.1
| |
Err returns the first non-EOF error that was encountered by the Scanner.
Err方法返回Scanner遇到的第一个非EOF错误。
(*Scanner) Scan <- go1.1
| |
Scan advances the Scanner to the next token, which will then be available through the Bytes or Text method. It returns false when the scan stops, either by reaching the end of the input or an error. After Scan returns false, the Err method will return any error that occurred during scanning, except that if it was io.EOF, Err will return nil. Scan panics if the split function returns too many empty tokens without advancing the input. This is a common error mode for scanners.
Scan方法将Scanner推进到下一个标记,然后可以通过Bytes或Text方法获得该标记。当扫描停止时,要么是到达输入的末尾,要么是发生了错误,则返回false。在Scan返回false之后,Err方法将返回扫描期间发生的任何错误,除非它是io.EOF,则Err将返回nil。如果分割函数返回太多的空标记而不推进输入,则Scan方法会panic。这是扫描器的常见错误模式。
(*Scanner) Split <- go1.1
| |
Split sets the split function for the Scanner. The default split function is ScanLines.
Split方法设置Scanner的分割函数。默认的分割函数是ScanLines。
Split panics if it is called after scanning has started.
如果在扫描开始后调用Split方法,会panic。
(*Scanner) Text <- go1.1
| |
Text returns the most recent token generated by a call to Scan as a newly allocated string holding its bytes.
Text方法返回最近一次Scan调用生成的token,以一个新分配的字符串形式返回。
type SplitFunc <- go1.1
| |
SplitFunc is the signature of the split function used to tokenize the input. The arguments are an initial substring of the remaining unprocessed data and a flag, atEOF, that reports whether the Reader has no more data to give. The return values are the number of bytes to advance the input and the next token to return to the user, if any, plus an error, if any.
SplitFunc类型是用于将输入进行分词的分割函数的类型。实参是剩余未处理数据的初始子字符串和一个标志atEOF,它报告Reader是否没有更多的数据可以提供。返回值是要推进输入的字节数,以及要返回给用户的下一个token(如果有的话),以及任何错误(如果有的话)。
Scanning stops if the function returns an error, in which case some of the input may be discarded. If that error is ErrFinalToken, scanning stops with no error.
如果该函数返回错误,扫描将停止,此时部分输入可能被丢弃。如果该错误是ErrFinalToken,则扫描将无错误停止。
Otherwise, the Scanner advances the input. If the token is not nil, the Scanner returns it to the user. If the token is nil, the Scanner reads more data and continues scanning; if there is no more data–if atEOF was true–the Scanner returns. If the data does not yet hold a complete token, for instance if it has no newline while scanning lines, a SplitFunc can return (0, nil, nil) to signal the Scanner to read more data into the slice and try again with a longer slice starting at the same point in the input.
否则,Scanner将推进输入。如果token不是nil,则Scanner将其返回给用户。如果token是nil,则Scanner读取更多数据并继续扫描;如果没有更多数据 —— 如果atEOF为true —— 则Scanner返回。如果数据还没有完整的token,例如在扫描行时没有换行符,SplitFunc可以返回(0,nil,nil)以表示Scanner将数据读取到slice中并尝试从相同的输入点开始的更长slice中再次尝试。
The function is never called with an empty data slice unless atEOF is true. If atEOF is true, however, data may be non-empty and, as always, holds unprocessed text.
除非atEOF为true,否则该函数永远不会使用空数据切片调用。但是,如果atEOF为true,则数据可能是非空的,并且一如既往地包含未处理的文本。
type Writer
| |
Writer implements buffering for an io.Writer object. If an error occurs writing to a Writer, no more data will be accepted and all subsequent writes, and Flush, will return the error. After all data has been written, the client should call the Flush method to guarantee all data has been forwarded to the underlying io.Writer.
Writer结构体实现了对io.Writer对象的缓存。如果写入Writer时发生错误,则不再接受更多数据,并且所有后续的写入和Flush都将返回该错误。在写入所有数据后,客户端应调用Flush方法以确保所有数据已转发到底层的io.Writer。
Writer Example
| |
func NewWriter
| |
NewWriter returns a new Writer whose buffer has the default size. If the argument io.Writer is already a Writer with large enough buffer size, it returns the underlying Writer.
NewWriter函数返回一个新的Writer,其缓冲区具有默认大小。如果参数io.Writer已经是具有足够大缓冲区大小的Writer,则返回底层Writer。
func NewWriterSize
| |
NewWriterSize returns a new Writer whose buffer has at least the specified size. If the argument io.Writer is already a Writer with large enough size, it returns the underlying Writer.
NewWriterSize函数返回一个新的 Writer,它的缓冲区大小至少为指定大小。如果 io.Writer 参数已经是具有足够大的大小的 Writer,则返回底层 Writer。
(*Writer) Available
| |
Available returns how many bytes are unused in the buffer.
Available方法返回缓冲区中未使用的字节数。
(*Writer) AvailableBuffer <- go1.18
| |
AvailableBuffer returns an empty buffer with b.Available() capacity. This buffer is intended to be appended to and passed to an immediately succeeding Write call. The buffer is only valid until the next write operation on b.
AvailableBuffer方法返回一个空的缓冲区,该缓冲区具有 b.Available() 容量。该缓冲区旨在附加到并传递给紧接着的 Write 调用。该缓冲区仅在 b 上的下一次写入操作之前有效。
AvailableBuffer Example
| |
(*Writer) Buffered
| |
Buffered returns the number of bytes that have been written into the current buffer.
Buffered方法返回已写入当前缓冲区的字节数。
(*Writer) Flush
| |
Flush writes any buffered data to the underlying io.Writer.
Flush方法将任何缓冲的数据写入底层 io.Writer。
(*Writer) ReadFrom <- go1.1
| |
ReadFrom implements io.ReaderFrom. If the underlying writer supports the ReadFrom method, this calls the underlying ReadFrom. If there is buffered data and an underlying ReadFrom, this fills the buffer and writes it before calling ReadFrom.
ReadFrom方法实现 io.ReaderFrom接口。如果底层写入器支持 ReadFrom 方法,则会调用底层 ReadFrom。如果存在缓冲数据和底层 ReadFrom,则在调用 ReadFrom 之前填充缓冲区并将其写入。
(*Writer) Reset <- go1.2
| |
Reset discards any unflushed buffered data, clears any error, and resets b to write its output to w. Calling Reset on the zero value of Writer initializes the internal buffer to the default size.
Reset方法丢弃任何未刷新的缓冲数据,清除任何错误,并将 b 重置为将其输出写入 w。在零值 Writer 上调用 Reset 会将内部缓冲区初始化为默认大小。
(*Writer) Size <- go1.10
| |
Size returns the size of the underlying buffer in bytes.
Size方法返回底层缓冲区的大小(以字节为单位)。
(*Writer) Write
| |
Write writes the contents of p into the buffer. It returns the number of bytes written. If nn < len(p), it also returns an error explaining why the write is short.
Write方法将 p 的内容写入缓冲区。它返回写入的字节数。如果 nn < len(p),它还会返回一个错误,解释为什么写入不足。
(*Writer) WriteByte
| |
WriteByte writes a single byte.
WriteByte方法写入一个单独的字节。
(*Writer) WriteRune
| |
WriteRune writes a single Unicode code point, returning the number of bytes written and any error.
WriteRune方法写入一个单独的 Unicode 码点,返回写入的字节数和任何错误。
(*Writer) WriteString
| |
WriteString writes a string. It returns the number of bytes written. If the count is less than len(s), it also returns an error explaining why the write is short.
WriteString方法写入一个字符串。它返回写入的字节数。如果写入的字节数少于 len(s),它还会返回一个错误,解释为什么写入不足。