在 Go 中构建基于LLM的应用程序
9 分钟阅读
Building LLM-powered applications in Go - 在 Go 中构建基于LLM的应用程序
Eli Bendersky 12 September 2024
2024年9月12日
As the capabilities of LLMs (Large Language Models) and adjacent tools like embedding models grew significantly over the past year, more and more developers are considering integrating LLMs into their applications.
随着LLM(大型语言模型)及其相关工具(如嵌入模型)的能力在过去一年中显著提升,越来越多的开发人员开始考虑将LLM集成到他们的应用程序中。
Since LLMs often require dedicated hardware and significant compute resources, they are most commonly packaged as network services that provide APIs for access. This is how the APIs for leading LLMs like OpenAI or Google Gemini work; even run-your-own-LLM tools like Ollama wrap the LLM in a REST API for local consumption. Moreover, developers who take advantage of LLMs in their applications often require supplementary tools like Vector Databases, which are most commonly deployed as network services as well.
由于LLM通常需要专用硬件和大量计算资源,因此它们通常作为网络服务提供,通过API进行访问。这也是OpenAI或Google Gemini等主流LLM API的工作方式;即使是像 Ollama 这样的自建LLM工具,也会通过REST API封装LLM,以便本地使用。此外,在应用程序中利用LLM的开发人员往往还需要使用诸如向量数据库之类的辅助工具,这些工具通常也作为网络服务进行部署。
In other words, LLM-powered applications are a lot like other modern cloud-native applications: they require excellent support for REST and RPC protocols, concurrency and performance. These just so happen to be the areas where Go excels, making it a fantastic language for writing LLM-powered applications.
换句话说,基于LLM的应用程序非常类似于其他现代的云原生应用程序:它们需要出色的REST和RPC协议支持、并发性和高性能。而这些正是Go语言的优势所在,这使得Go成为编写基于LLM的应用程序的理想语言。
This blog post works through an example of using Go for a simple LLM-powered application. It starts by describing the problem the demo application is solving, and proceeds by presenting several variants of the application that all accomplish the same task, but use different packages to implement it. All the code for the demos of this post is available online.
这篇博客通过一个简单的基于LLM的应用示例展示了如何使用Go构建这样的应用程序。它首先描述了该示例应用程序所要解决的问题,然后介绍了几个不同的实现变体,这些变体都完成了相同的任务,但使用了不同的包来实现。所有示例代码都可以在线获取。
用于问答的RAG服务器 A RAG server for Q&A
A common LLM-powered application technique is RAG - Retrieval Augmented Generation. RAG is one of the most scalable ways of customizing an LLM’s knowledge base for domain-specific interactions.
一个常见的基于LLM的应用技术是RAG - 检索增强生成。RAG是为领域特定交互定制LLM知识库的最具可扩展性的方法之一。
We’re going to build a RAG server in Go. This is an HTTP server that provides two operations to users:
我们将在Go中构建一个 RAG 服务器。这是一个HTTP服务器,向用户提供两个操作:
Add a document to the knowledge base
将文档添加到知识库中
Ask an LLM a question about this knowledge base
向LLM询问有关该知识库的问题
In a typical real-world scenario, users would add a corpus of documents to the server, and proceed to ask it questions. For example, a company can fill up the RAG server’s knowledge base with internal documentation and use it to provide LLM-powered Q&A capabilities to internal users.
在典型的实际场景中,用户将文档集添加到服务器,然后询问它问题。例如,一家公司可以将内部文档填充到RAG服务器的知识库中,用于向内部用户提供基于LLM的问答功能。
Here’s a diagram showing the interactions of our server with the external world:
下图展示了我们的服务器与外部世界的交互方式:
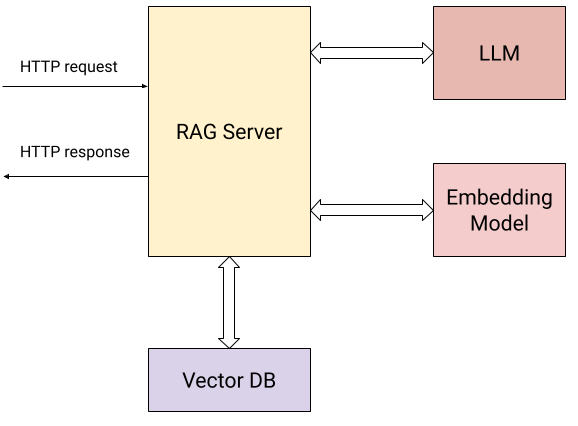
In addition to the user sending HTTP requests (the two operations described above), the server interacts with:
除了用户发送的HTTP请求(如上所述的两个操作),该服务器还与以下组件交互:
- An embedding model to calculate vector embeddings for the submitted documents and for user questions.
- 一个嵌入模型,用于计算提交文档和用户问题的向量嵌入。
- A Vector Database for storing and retrieving embeddings efficiently.
- 一个向量数据库,用于高效存储和检索嵌入。
- An LLM for asking questions based on context collected from the knowledge base.
- 一个LLM,用于根据从知识库中收集的上下文回答问题。
Concretely, the server exposes two HTTP endpoints to users:
具体来说,服务器向用户公开了两个HTTP端点:
/add/: POST {"documents": [{"text": "..."}, {"text": "..."}, ...]}: submits a sequence of text documents to the server, to be added to its knowledge base. For this request, the server:
/add/: POST {"documents": [{"text": "..."}, {"text": "..."}, ...]}:提交一系列文本文档到服务器,以添加到知识库中。对于该请求,服务器:
- Calculates a vector embedding for each document using the embedding model. 使用嵌入模型为每个文档计算向量嵌入。
- Stores the documents along with their vector embeddings in the vector DB. 将文档及其向量嵌入存储到向量数据库中。
/query/: POST {"content": "..."}: submits a question to the server. For this request, the server:
/query/: POST {"content": "..."}:向服务器提交一个问题。对于该请求,服务器:
- Calculates the question’s vector embedding using the embedding model.
- 使用嵌入模型计算问题的向量嵌入。
- Uses the vector DB’s similarity search to find the most relevant documents to the question in the knowledge database.
- 使用向量数据库的相似性搜索在知识库中找到与问题最相关的文档。
- Uses simple prompt engineering to reformulate the question with the most relevant documents found in step (2) as context, and sends it to the LLM, returning its answer to the user.
- 使用简单的提示工程,将问题与步骤2中找到的最相关文档作为上下文进行重新构造,并发送给LLM,返回其答案给用户。
The services used by our demo are:
我们示例中使用的服务是:
- Google Gemini API for the LLM and embedding model. Google Gemini API 用于LLM和嵌入模型。
- Weaviate for a locally-hosted vector DB; Weaviate is an open-source vector database implemented in Go. Weaviate 用于本地托管的向量数据库;Weaviate 是一个 用Go实现的 开源向量数据库。
It should be very simple to replace these by other, equivalent services. In fact, this is what the second and third variants of the server are all about! We’ll start with the first variant which uses these tools directly.
实际上,替换这些服务为其他等效服务非常简单。事实上,服务器的第二和第三个变体就是围绕这一点展开的!我们将从使用这些工具的第一个变体开始。
直接使用Gemini API和Weaviate - Using the Gemini API and Weaviate directly
Both the Gemini API and Weaviate have convenient Go SDKs (client libraries), and our first server variant uses these directly. The full code of this variant is in this directory.
Gemini API和Weaviate都有便捷的Go SDK(客户端库),我们第一个服务器变体直接使用这些工具。该变体的完整代码可以在这个目录中找到。
We won’t reproduce the entire code in this blog post, but here are some notes to keep in mind while reading it:
我们不会在此重复所有代码,但在阅读时需要注意以下几点:
Structure: the code structure will be familiar to anyone who’s written an HTTP server in Go. Client libraries for Gemini and for Weaviate are initialized and the clients are stored in a state value that’s passed to HTTP handlers.
结构:对于熟悉Go中编写HTTP服务器的人来说,代码结构应该很熟悉。Gemini和Weaviate的客户端库被初始化,客户端存储在状态值中并传递给HTTP处理程序。
Route registration: the HTTP routes for our server are trivial to set up using the routing enhancements introduced in Go 1.22:
路由注册:使用Go 1.22中引入的 路由增强,设置服务器的HTTP路由非常简单:
| |
Concurrency: the HTTP handlers of our server reach out to other services over the network and wait for a response. This isn’t a problem for Go, since each HTTP handler runs concurrently in its own goroutine. This RAG server can handle a large number of concurrent requests, and the code of each handler is linear and synchronous.
并发性:服务器的HTTP处理程序通过网络与其他服务交互并等待响应。这对于Go来说不是问题,因为每个HTTP处理程序都在自己的协程(goroutine)中并发运行。这个RAG服务器可以处理大量并发请求,每个处理程序的代码都是线性的和同步的。
Batch APIs: since an /add/ request may provide a large number of documents to add to the knowledge base, the server leverages batch APIs for both embeddings (embModel.BatchEmbedContents) and the Weaviate DB (rs.wvClient.Batch) for efficiency.
批量API:由于 /add/ 请求可能会提交大量文档到知识库,服务器为了效率,利用了嵌入模型的批量API(embModel.BatchEmbedContents)和Weaviate数据库的批量API(rs.wvClient.Batch)。
使用LangChain for Go - Using LangChain for Go
Our second RAG server variant uses LangChainGo to accomplish the same task.
我们的第二个RAG服务器变体使用LangChainGo来完成相同的任务。
LangChain is a popular Python framework for building LLM-powered applications. LangChainGo is its Go equivalent. The framework has some tools to build applications out of modular components, and supports many LLM providers and vector databases in a common API. This allows developers to write code that may work with any provider and change providers very easily.
LangChain 是一个流行的Python框架,用于构建基于LLM的应用程序。LangChainGo 是其Go版本。该框架提供了一些工具来通过模块化组件构建应用程序,并支持许多LLM提供者和向量数据库,使用一个通用API。这使得开发人员能够编写适用于任何提供者的代码,并轻松切换提供者。
The full code for this variant is in this directory. You’ll notice two things when reading the code:
该变体的完整代码位于这个目录。阅读代码时,您会注意到两点:
First, it’s somewhat shorter than the previous variant. LangChainGo takes care of wrapping the full APIs of vector databases in common interfaces, and less code is needed to initialize and deal with Weaviate.
首先,代码比前一个变体稍短。LangChainGo负责将向量数据库的完整API封装到通用接口中,因此初始化和处理Weaviate所需的代码更少。
Second, the LangChainGo API makes it fairly easy to switch providers. Let’s say we want to replace Weaviate by another vector DB; in our previous variant, we’d have to rewrite all the code interfacing the vector DB to use a new API. With a framework like LangChainGo, we no longer need to do so. As long as LangChainGo supports the new vector DB we’re interested in, we should be able to replace just a few lines of code in our server, since all the DBs implement a common interface:
其次,LangChainGo的API使切换提供者变得相对容易。假设我们想将Weaviate替换为另一个向量数据库;在之前的变体中,我们需要重写所有与向量数据库接口的代码以使用新的API。而使用LangChainGo框架,只要LangChainGo支持我们感兴趣的新向量数据库,我们只需替换服务器中的几行代码,因为所有数据库都实现了通用接口:
| |
使用Genkit for Go - Using Genkit for Go
Earlier this year, Google introduced Genkit for Go - a new open-source framework for building LLM-powered applications. Genkit shares some characteristics with LangChain, but diverges in other aspects.
今年早些时候,Google推出了Genkit for Go - 一个用于构建基于LLM的应用程序的新开源框架。Genkit与LangChain有一些共同特征,但在某些方面有所不同。
Like LangChain, it provides common interfaces that may be implemented by different providers (as plugins), and thus makes switching from one to the other simpler. However, it doesn’t try to prescribe how different LLM components interact; instead, it focuses on production features like prompt management and engineering, and deployment with integrated developer tooling.
与LangChain一样,它提供了可以由不同提供者(作为插件)实现的通用接口,因此简化了从一个提供者切换到另一个提供者的操作。然而,它不试图规定不同的LLM组件如何交互;相反,它专注于生产环境功能,如提示管理和工程,以及集成开发工具的部署。
Our third RAG server variant uses Genkit for Go to accomplish the same task. Its full code is in this directory.
我们的第三个RAG服务器变体使用Genkit for Go来完成相同的任务。其完整代码位于这个目录。
This variant is fairly similar to the LangChainGo one - common interfaces for LLMs, embedders and vector DBs are used instead of direct provider APIs, making it easier to switch from one to another. In addition, deploying an LLM-powered application to production is much easier with Genkit; we don’t implement this in our variant, but feel free to read the documentation if you’re interested.
这个变体与LangChainGo的实现非常相似 - LLM、嵌入模型和向量数据库使用通用接口而不是直接的提供者API,使得从一个提供者切换到另一个提供者变得更容易。此外,使用Genkit,部署基于LLM的应用程序到生产环境变得更加简单;我们没有在这个变体中实现这个功能,但如果您感兴趣,可以阅读文档。
总结 - Go用于基于LLM的应用程序 Summary - Go for LLM-powered applications
The samples in this post provide just a taste of what’s possible for building LLM-powered applications in Go. It demonstrates how simple it is to build a powerful RAG server with relatively little code; most important, the samples pack a significant degree of production readiness because of some fundamental Go features.
本文中的示例只是展示了在Go中构建基于LLM的应用程序的可能性的一小部分。它展示了如何用相对较少的代码构建一个强大的RAG服务器;最重要的是,由于Go的某些基础功能,这些示例具有很强的生产就绪性。
Working with LLM services often means sending REST or RPC requests to a network service, waiting for the response, sending new requests to other services based on that and so on. Go excels at all of these, providing great tools for managing concurrency and the complexity of juggling network services.
与LLM服务协作通常意味着向网络服务发送REST或RPC请求,等待响应,然后根据响应向其他服务发送新请求。Go在这些方面表现出色,提供了优秀的工具来管理并发性和处理网络服务的复杂性。
In addition, Go’s great performance and reliability as a Cloud-native language makes it a natural choice for implementing the more fundamental building blocks of the LLM ecosystem. For some examples, see projects like Ollama, LocalAI, Weaviate or Milvus.
此外,Go作为云原生语言,具有卓越的性能和可靠性,使其成为实现LLM生态系统中更多基础构建块的自然选择。有关一些示例,请参见像 Ollama、LocalAI、Weaviate 或 Milvus 等项目。